![[The CEE Flag]](../../../home/_home/_logos/ue.gif)
![[Joint Research Center European Commission]](../../../home/_home/_logos/jrc.jpg)
![[Institute for Systems, Informatics and Safety]](../../../home/_home/_logos/isis_m.jpg)
 |
Kepler
University
|
|
|
|
|
|
|
|
|
|
|
|
DE-4104 VOICE
PROJECT ACCOMPANYING MEASURE
Due to the increasing power and the decreasing costs of PCs speech input technology has witnessed significant progress the last years. Speech input systems are used for text and command input for Human-Computer Interaction (HCI). In addition to that possibilities to support the interpersonal communication are sorted out. Especially for users with disabilities having problems in using standard interaction methods and problems with interpersonal communication new and efficient tools can be found. The EU funded project "VOICE", co-ordinated by JRC-ISIS - Joint Research Centre of the European Commission, Institute for Systems, Informatics and Safety – provided the framework for research on this topic. Beside JRC- ISIS the University of Linz, Austria and FBL S.r.l. Information Technologies, Mortara, Italy took part in the project. The main objective was to raise awareness for the capabilities of speech input for people with disabilities, especially for hard of hearing and deaf people. Materials and deliverables are available on the Internet and in printed format at: http://voice.jrc.it The following pages outline the results of a survey done to find out the level of usage and usability of speech input systems for people with disabilities. Although the potential of this technology seems to be obvious application in practice seems to be rather low. This asks for users' needs analysis to sort out usability problems. The centre of gravity will be given to the access to spoken language of hard of hearing and deaf people. A prototype of a subtitling system using of the shelf speech recognition engines was developed and tested. Aknowledgements This work was performed in the framework of the VOICE project (DE4104 - Disabled and Elderly funded by the European Commission, DG Information Society, by means of its Telematics Applications Programme (TAP). This report is a summary of Deliverable 4.1 and 4.2 of the VOICE project. State
of the Art of Speech Input Technology - Speech is the most important, most complex and most human tool for communication and interaction. We build our understanding of the world and of each other on verbal language based interaction and communication. Therefore the possibility to use speech for HCI, for putting in text and commands has been part of wishful science fiction and is getting more and more an exciting challenge for engineering and interdisciplinary research. Verbal communication goes far beyond a simple transfer of information. When interacting with a machine one gets to know that more than talking to a microphone is required. Even the smallest differences to human communication will be recognised and will influence usability. The whole environmental setting is influenced when speech input is employed. This leads to a mismatch between users' estimations, expectations and practical application of speech input systems. Although the quality of these systems is already very high and appreciated, users, after short trials, go back to standard modes of interaction. Speech input meats with users' fascination and initial enthusiasm but not with their needs in everyday practice. Voice recognition is a step forward towards a user friendlier access and usage of computers. This gets most important for those users who are not able to use standard interaction methods either because of functional limitations in special situations (e.g. a car driver who has to keep his hands on the wheel when he wants to fulfil other tasks like handling the radio, the GPS device, the mobile telephone or other) or because of functional limitations caused by an impairment. Often not more than an alternative for ordinary users, speech input could become an important tool for "extra-ordinary" users. Although the basic concepts of speech input technology were defined already in the 70ies and 80ies useful applications got available only in the 90ies. Several improvements of the Man-Machine Interaction (MMI) and the usability of speech recognition systems could be achieved.
The step from recognition of disjointed speaking to continuous speaking has been the starting point for a wide area of applications. Today text input via fluent speech into standard applications or commanding and controlling the desktop is possible.
Today the following most critical areas for achieving good recognition results should be taken into account:
In the future speech input will be used, beside dictating and commanding, for language/speaker recognition, speech understanding, non-speech sound and object recognition offering additional interesting perspectives for HCI. Where you can look for further information:
The centre of gravity in the "VOICE" project was given to an easier and more complete access to spoken language for hard of hearing and deaf people. A special system, first called "VOICE prototype" and now "VOICE meeting" was developed. This system provides an interface to speech using subtitles. The "VOICE meeting" system is a multimedia workstation applying, dependant of the situation of use, a lot of technology like powerful multimedia PC, video camera, video recorder/TV and wall projector. Off the shelf speech input packages are a basically assistive devices for a hard of hearing and deaf people. But systems are designed to input text into applications. This leads to fundamental usability problems when speech input should be used for communication purposes. Recognised text normally is displayed in windows designed for a single user fulfilling other tasks and not for communication. To keep the attention on the communication any disturbance should be avoided. Interfaces to other applications should be hidden. Only when necessary interfaces to the recognition engine, the communication tool and other applications should be displayed. An other basic requirement of such a tool is the need that the recognised text and other media as descriptive images (e.g. pictures, slides, graphs) and videos, especially the face of the speaker, should get as much as possible space on the screen. When a sense is missing or restricted switching between available methods of access (e.g. from speaker's lips to recognised text and vice versa) gets most important. Deaf and hard of hearing listeners therefore also want to lip-read during subtitled communication. Problems occur when speakers move around in the room what changes the distance between speakers' face and the subtitles. Therefore the system can integrate live video of the speaker. Lip reading lets some uncertainty in interpreting the words and is – dependent on the awareness of the speaker – often interrupted. Errors in subtitles may lead to misunderstandings. A combination of lip reading and subtitles could reduce the danger that users may loose track during a presentation.
Starting from these basic requirements a subtitling programme was developed. "VOICE meeting" provides an interface to speech using subtitles and is tailored for purposes like
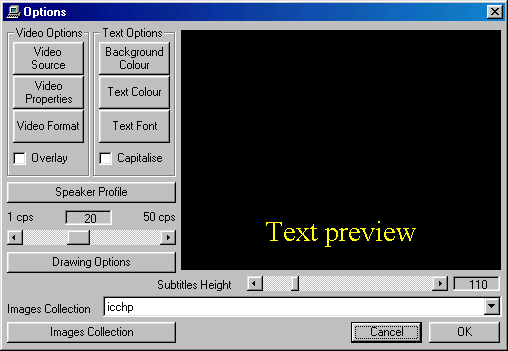
"VOICE meeting" reserves the whole screen for communication. A simple one-line toolbar provides the interface to all necessary interactions with the speech recognition engine (e.g. microphone on/off, speaker profile, language) as well as with the "VOICE meeting" software. This menu pops up on the screen when the mouse cursor passes the area of the interface on the desktop. Therefore "VOICE meeting reserves the whole interface to subtitles and images. The basic functionalities described above turn voice recognition engines into a subtitling system. The interface can be defined in a way, which suits the needs of a certain situation best. The number of lines and their length can be defined. The text is displayed in a textbox on a definable background colour. Font, colour and size of text can be defined. Words are never split up in two lines (no hyphenation) to improve readability. An important feature is the setting of the duration, which the text has to remain on the screen for reading. This asks for a certain style of speaking when the audience involves listeners using or being dependent on subtitles, especially hard of hearing and deaf people. A short pause (greater than 250 msec) should be made which tells the system to complete the recognition process (an other 250 msec). Short sentences should be used to allow participants also to lip-read. For each speaker it will be necessary to use such a time span to be able and to allow to co-ordinate speaking, recognition, displaying, perception and understanding. Such a style of speaking also allows the speaker to proof-read the recognised text and, if necessary, to repeat some words that have not been recognised correctly. If necessary the keyboard may be used to type some specific words.
An additional important feature is the possibility to save recognised text (reference, reports, minutes). Especially for the target group of hard of hearing and deaf people this offers at least access "a posteriori" to fragmentary spoken language. Additional functionalities enable the user to integrate slides, images, videos, … by simply using predefined voice commands. Parameters like duration of appearance or keywords to disappear are included. Users' Needs Analysis of Speech Input Systems Almost any article on speech technology outlines the high potential of speech recognition as a substitution or addition to standard interaction methods to input text or commands at the MMI. These systems would make flexible and efficient HCI possible. A significant number of articles mention the high potential of speech input technology for people with disabilities. Those having problems with standard interaction methods would benefit most of this technology. This seems to be obvious and of high practical value at a first glance. Nevertheless an intensive and broad usage cannot be found in practice. Although available at a low price and with high quality speech recognition only got widely used in some specific areas (e.g. medicines, telephone operator). The VOICE project was confronted with and gave evidence to this gap between potential and use. Users' needs analysis was performed to find out reasons for that and possibilities to overcome this situation. The state-of-the-art in usability research was evaluated. A focus was given to usability, user centred design and design for all for people with disabilities. The body of knowledge available in most parts refers on the process of the development and/or evaluation of HCI. It does not refer on the specific situation of application and the impact on the organisational and environmental settings. Following this study several tests of speech input systems and the "VOICE meeting" system with users with disabilities and experts in the field were performed. Questionnaires and interview/discussion guides were used as well as notes were taken in all tests, training and presentations. The main results may be resumed in the following points:
Users' needs analysis of The "VOICE Meeting" System The usability of speech input systems are also applicable for "VOICE meeting", which uses standard speech recognition engines. The needs concerning the presentation situation will be discussed here.
Conclusions and Recommendations Being closely related with language, the most complex and most human tool on which we base our understanding of each other and of reality, speech recognition has to be applied very carefully. Rather often users and experts, although enthusiastic at the beginning, do not take the necessary efforts into account. Training and practice needed to reach a level where one really could benefit from this technology is not estimated. There are wrong estimations about an easy to use technology. There is a lack of awareness on the needs for practice. Information, case studies, practical examples and methodological guides should help to avoid wrong estimations and frustration in order to put the high potential into practice. People are concerned that a system like "VOICE meeting" would be really applicable in practice. This is estimated not because of the technology but because of the preparation needed and the standard style of interaction and communication, which is interrupted by this a technology. There are of course special areas for useful application (e.g. special school, TV subtitling, taking notes). This shows that although a considerable body of knowledge is available concerning accessibility and usability of HCI generally and for people with disabilities especially there is a need for further research and engagement to put the potential of speech input systems and systems like "VOICE meeting" into action. In any case systems like "VOICE meeting" have to be seen as first steps towards a user friendlier and more adaptable use of spoken language at the MMI. All problems encountered should be seen as invitations for further research and development activities. February 2001 |


| <Home> <Projects> <TAP> <User Requirements> |